Wielu dyrektorów w dużych firmach ma dziś otwartych 10-15 pilotażowych projektów Generatywnej AI. Wydali już pewnie z pół miliona euro na chmurę, tokeny API i modne „sprinty innowacyjne”. A mimo to – i to jest kluczowe – na produkcji nie działa ani jedno wdrożenie mission-critical.
To nie jest problem z brakiem innowacyjnośc, tylko z brakiem weryfikacji.
Portfele projektów są pełne „zombie pilotów”. To projekty, które technicznie żyją (serwery szumią, diody mrugają), ale biznesowo są martwe. Dostały zielone światło na fali entuzjazmu zarządu i ogólnego „hype’u”, ale teraz utknęły w martwym punkcie między efektownym demo a wdrożeniem na dużą skalę.
Dziś zajrzymy pod maskę i spojrzymy na inżynieryjną prawdę o tym zjawisku. Pokażę „Kryteria Eliminacji” (Kill Criteria) – proste narzędzia potrzebne do tego, by bezlitośnie wyciąć 80% (a może i 95%) projektów, które tylko palą zasoby. Tylko tak zrobisz miejsce na skalowanie tego, co naprawdę ma sens.
Audyt „Kryteriów Eliminacji”#
Wielkie firmy konsultingowe, sprzedając pilotaże, rzadko mówią o jednym sekrecie branży: 95% projektów GenAI wykłada się na etapie skalowania. Wszystko działa pięknie na 500 wybranych dokumentach w bezpiecznej piaskownicy. Ale wrzuć ten sam model w bagno 50 000 realnych, firmowych plików, a system się posypie.
Nazywamy to „Gniciem RAG” (RAG Rot). I nie naprawimy tego „lepszymi promptami”. To wymaga twardej inżynierii.
Ważne rozróżnienie: Projekt może upaść z wielu powodów. Kiepskie dane, blokady prawne (RODO/AI Act) czy ryzyko wizerunkowe to solidne podstawy do zamknięcia tematu. To standardowe bramki nadzorcze. Dziś skupimy się jednak wyłącznie na błędach inżynieryjnych i ekonomicznych. To cisi zabójcy, często ignorowane przez działy innowacji, dopóki nie jest za późno.
Oto anatomia porażki i konkretne kryteria, jak audytować takie projekty.
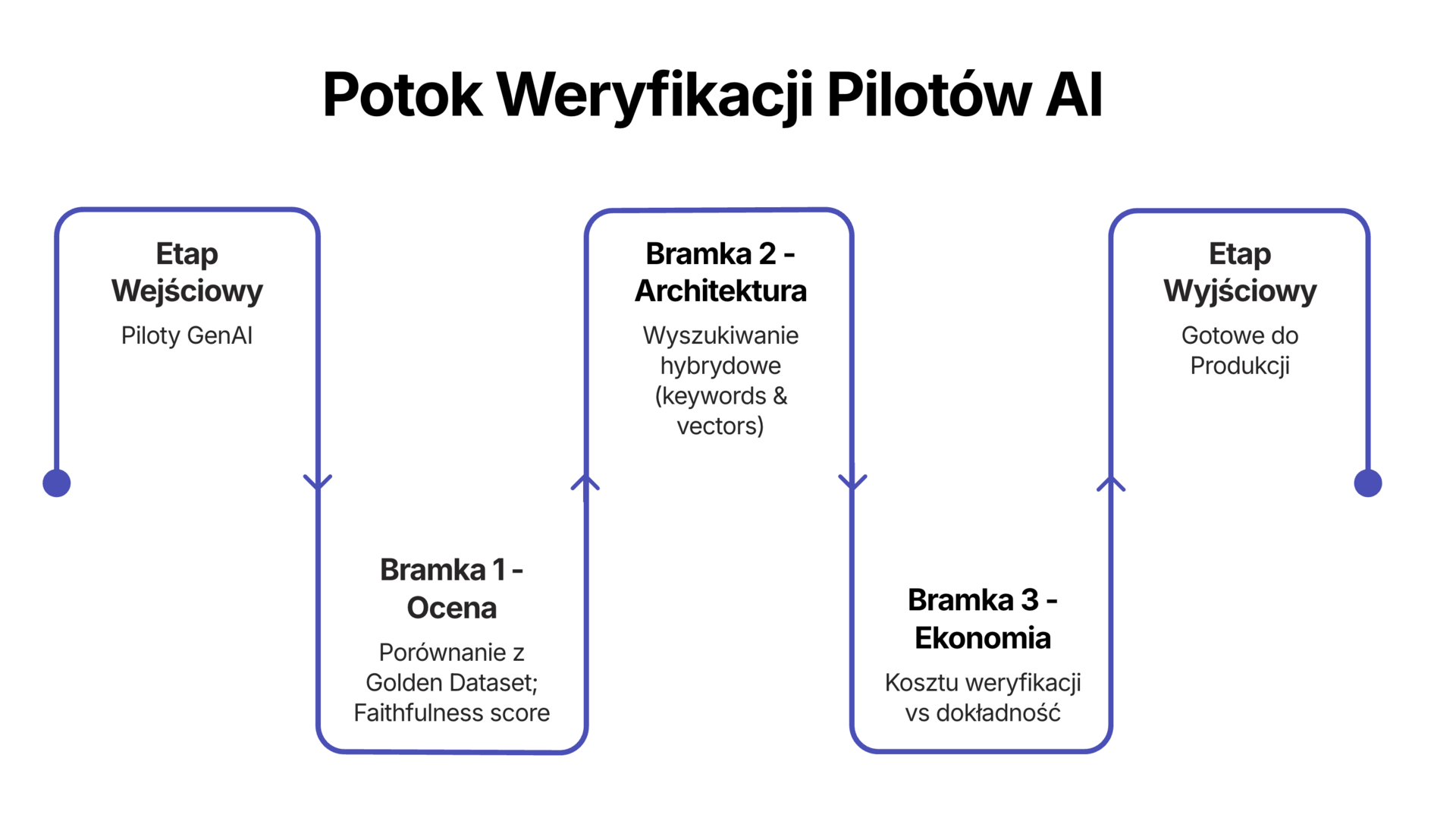
1. „Test na oko” vs. twardy test#
W wielu korporacjach pilotaże ocenia się „na oko”. Deweloper pokazuje chatbota szefowi sprzedaży, ten zadaje mu kilka pytań o wyniki kwartalne w Q3, bot odpowiada z sensem i odtrąbiamy sukces.
To absurd. Nie budujemy mostów „na oko”, więc dlaczego akceptujemy to przy oprogramowaniu, które z natury — w przypadku GenAI — działa stochastycznie? Taka weryfikacja jest ślepa na błędy pojawiające się z czasem (drift) i na rzadkie, ale krytyczne przypadki brzegowe.
Diagnoza: Jeśli zespół nie potrafi pokazać automatycznie wygenerowanego wyniku skuteczności (Eval score), to nie masz do czynienia z oprogramowaniem, tylko z jednorazową sztuczką.
Kryterium eliminacji: Zażądaj wartości Faithfulness Score. To wskaźnik mówiący, czy to, co wygenerowała AI, faktycznie wynika z dostarczonych danych. Jeśli zespół nie ma takich metryk lub wynik jest poniżej 0,9 – projekt idzie do kosza albo do gruntownej przebudowy.
Naprawa: Wprowadź zasadę „rozwoju opartego na ewaluacji” (Evaluation-Driven Development). Zanim powstanie linijka kodu, tworzymy „golden dataset” – 100 pytań i 100 poprawnych odpowiedzi. Każda aktualizacja modelu musi przejść test na tym zbiorze. Narzędzia takie jak Ragas czy DeepEval dadzą ci twarde dane:
Faithfulness: Czy AI zmyśla?
Context Precision: Czy system w ogóle znalazł właściwy dokument, czy tylko miał szczęście?
Zasada jest prosta: czego nie możesz zmierzyć, tego nie możesz wdrożyć.
2. Gnicie RAG: dlaczego wasza baza wiedzy jest toksyczna#
RAG (Retrieval-Augmented Generation) to dziś standard. AI szuka dokumentów, a potem je streszcza. Wszystko gra, dopóki nie zaczniemy wdrożenia na dużą skalę.
Problem „środka” (Lost in the Middle): Modele językowe mają swoją „wadę poznawczą”. Świetnie pamiętają początek i koniec tekstu, ale gubią to, co w środku. Jeśli system podsunie AI 20 dokumentów, a kluczowa informacja będzie w dziesiątym, model prawdopodobnie ją pominie.
Zatruwanie kontekstu: W demo dane są sterylne. W produkcji – bywa to śmietnik. Wystarczy, że ktoś (złośliwie albo z lenistwa) wrzuci do bazy PDF zatruwający dane, np z ukrytymi instrukcjami, a model zgłupieje. Jeden „zatruty” dokument może podważyć wiarygodność całej odpowiedzi.
Kryterium eliminacji: Zapytaj inżynierów: „Jak dokładnie wyszukujemy informacje?”. Jeśli usłyszysz: „Używamy standardowego wyszukiwania wektorowego”, projekt jest skazany na porażkę przy dużej skali. Zwykłe wektory są „głupie” – łapią słowa kluczowe, ale gubią sens.
Naprawa: Potrzebne jest wyszukiwanie hybrydowe z etapem re-rankingu. W dużej organizacji to nie jest opcja, tylko wymóg. Używa się do tego „cross-encodera” – mądrzejszego, choć wolniejszego modelu, który sprawdza to, co znalazło szybkie wyszukiwanie. Dzięki temu AI dostaje tylko to, co naprawdę istotne. Tak, system zwolni o 300 milisekund. Ale 300 ms opóźnienia to niska cena za uniknięcie 10% halucynacji.
3. Koszt weryfikacji, czyli finansowa pułapka#
To finansowa przyczyna większości porażek. Inwestycje w AI uzasadnia się oszczędnością czasu drogich specjalistów. Ale pomija się koszty weryfikacji.
Jeśli AI przygotuje umowę w 30 sekund (koszt: 2 zł), ale doświadczony prawnik musi spędzić 2 godziny na sprawdzaniu każdego przecinka, bo nie ufa maszynie (koszt: 800 zł), nie ma mowy o oszczędnościach, są straty.
To dług weryfikacji. Każda niepewna odpowiedź AI to dług, który człowiek spłaca swoim czasem. Na dodatek sprowadzasz swoich najlepszych ludzi do roli „sprawdzaczy AI”, co jest prostą drogą do frustracji i wypalenia.
- Kryterium eliminacji: Policz Cost Per Successful Query (CPSQ) – koszt udanej odpowiedzi.
$$ CPSQ = \frac{\text{Koszt infrastruktury}+\text{Koszt czasu weryfikacji}}{\text{Liczba udanych odpowiedzi}} $$
Jeśli ten wynik jest wyższy niż koszt wykonania zadania ręcznie, masz do czynienia z projektem „zombie”. Każde jego użycie to palenie pieniędzy.
Naprawa:
Bez litości dla niskiej dokładności. Jeśli model nie osiąga 95% samodzielnej skuteczności, koszty sprawdzania go zabiją zysk.
Samokontrola. System musi umieć ocenić własną pracę. Jeśli model nie jest pewien odpowiedzi, powinien powiedzieć „nie wiem”, zamiast zgadywać. „Nie wiem” jest nieskończenie tańsze niż brzmiące wiarygodnie kłamstwo.
Briefing#
Etyka to teraz twarda infrastruktura i geopolityka#
Najnowszy raport Montreal AI Ethics Institute to w praktyce nekrolog dla ery „miękkiej etyki”. Widzimy wyraźny zwrot: „AI Safety” zmienia się w „AI Security”, a napędzają go rozjeżdżające się regulacje w USA, Chinach i UE.
Dla lidera oznacza to dwa realne ryzyka:
Ograniczenia zasobowe: Zużycie zasobów przez centra danych przestaje być tylko przypisem w raporcie ESG. Staje się twardym ograniczeniem operacyjnym.
Pułapka suwerenności: Jeśli cały twój stack technologiczny opiera się na zagranicznych API, stabilność operacyjna twojej firmy zależy od geopolityki.
⠀ Wniosek: Etyka to nie PR. To teraz odporność łańcucha dostaw i zgodność z prawem. Jeśli twoja strategia opiera się na ogólnych hasłach, a nie na inżynieryjnej kontroli nad tym, gdzie i jak przetwarzasz dane, narażasz firmę na ryzyko.
Problem z ROI leży w ludziach, nie w technologii#
Analiza Harvard Business Review tłumaczy, dlaczego 95% pilotaży kończy się fiaskiem: traktujecie wdrożenie AI jak zakup oprogramowania, a to w rzeczywistości wyzwanie behawioralne.
Raport wymienia trzy „ludzkie błędy”, które zabijają zyski:
Lęk przed stratą: Pracownicy wolą nieefektywne, ręczne metody, bo boją się utraty autonomii bardziej, niż cieszy ich wzrost wydajności.
Brak wybaczania: Ludzie wybaczą koledze pomyłkę. AI skreślą po jednym błędzie.
Zbyt gładko: Jeśli AI działa zbyt niezauważalnie, ludzie tracą poczucie kontroli i przestają jej używać. Potrzebne jest wprowadzenia celowego „tarcia”, które wymusza zaangażowanie.
⠀ Wniosek: Przestańcie skupiać się na wagach modelu, zacznijcie projektować psychologię wdrożenia.
Zmień narrację: AI to „wzmacniacz”, nigdy „zastępstwo”.
Projektuj nadzór: Wymuszaj akceptację człowieka w kluczowych momentach. To przywraca zaufanie.
Zaangażuj ludzi: Jeśli użytkownicy nie pomagali tworzyć danych treningowych, odrzucą wynik.
Problem z „agentami” to problem zarządzania#
Raport Capgemini dotyczący wykorzystania GenAI w marketingu pokazuje przepaść: 70% szefów marketingu wierzy w autonomiczne agenty AI, ale tylko 7% widzi realne efekty.
Dlaczego? Bo struktura firmy nie nadąża:
Utrata sterowności: 55% projektów AI finansuje IT, a nie marketing. Marketing traci wpływ na kluczowe narzędzia.
Udawana automatyzacja: Mimo szumu, zespoły wciąż ręcznie obsługują narzędzia AI, zamiast zarządzać autonomicznymi agentami.
⠀ Wniosek: To błąd w zarządzaniu (governance). Marketing nie wdroży skutecznych agentów, jeśli budżet trzyma IT, które nie rozumie specyfiki biznesu.
Naprawa: AI to nie jest zwykły zakup IT.
Test: Jeśli twój „agent AI” nie potrafi sam zamknąć prostego zgłoszenia bez pomocy człowieka, jest po prostu chatbotem. Jeśli zamyka wszystkie bez nadzoru — narażasz się na ogromne ryzyko
Działanie: Marketing ustala zasady i cele, IT daje infrastrukturę i bezpieczeństwo.
Podsumowanie — pytanie na poniedziałkowy poranek#
Na najbliższym spotkaniu statusowym zadaj liderowi zespołowi technicznego jedno proste pytanie:
„Pokaż mi wynik ‘Wierności’ (Faithfulness) dla naszego głównego pilotażu i testy, w oparciu na których jest wyliczony”.
Jeśli zobaczysz puste spojrzenie albo tabelkę w Excelu, gdzie project manager wpisał „Działa OK”, wstrzymaj projekt. Lecicie na ślepo.
Wiem, że patrząc na dashboard z 15 „zielonymi” projektami, które nigdy nie wchodzą na produkcję, trudno o obiektywną ocenę. Jeśli potrzebujesz wsparcia w zastosowaniu tych kryteriów w swoich projektach albo chcesz po prostu sprawdzić, czy wasza strategia AI ma sens – daj znać.
Do następnego razu,
Krzysztof