It is time for an uncomfortable conversation about innovation portfolios.
Many enterprise executives currently have between 10 and 15 Generative AI pilots running. €500,000 has been spent on cloud credits, API fees, and “innovation sprints.” And, crucially, there are zero mission-critical deployments in production.
This is not a problem of “innovation” but of evaluation.
Portfolios are currently filled with “Zombie Pilots”—projects that are technically alive (the servers are running) but economically dead. They were approved based on “vibes” and executive enthusiasm, but they are now rotting in the transition from demo to scale.
Today, we look at the engineering reality of why this happens, and the “Kill Criteria” required to ruthlessly cull the 80% (or 95) of projects draining resources, enabling the scaling of the rest that matters.
The “Kill Criteria” Audit#
The industry secret that Big Consulting won’t share while selling the pilot is that 95% of GenAI pilots fail to scale. They work beautifully on a curated dataset of 500 documents in a sandbox. But when exposed to the messy, noisy reality of 50,000 enterprise files, they collapse.
We call this “RAG Rot.” And it isn’t solved by “better prompting.” It is solved by rigorous engineering.
A Critical Distinction: A pilot can fail (or be failed) for many reasons. Poor data quality, legal blockers (GDPR/EU AI Act), or reputational risks are all valid death sentences. Those are standard governance gates. Today, we focus specifically on the Engineering and Unit Economic criteria—the silent killers that innovation labs frequently miss until it is too late.
Here is the autopsy of a failed pilot, and the specific criteria required to audit them.
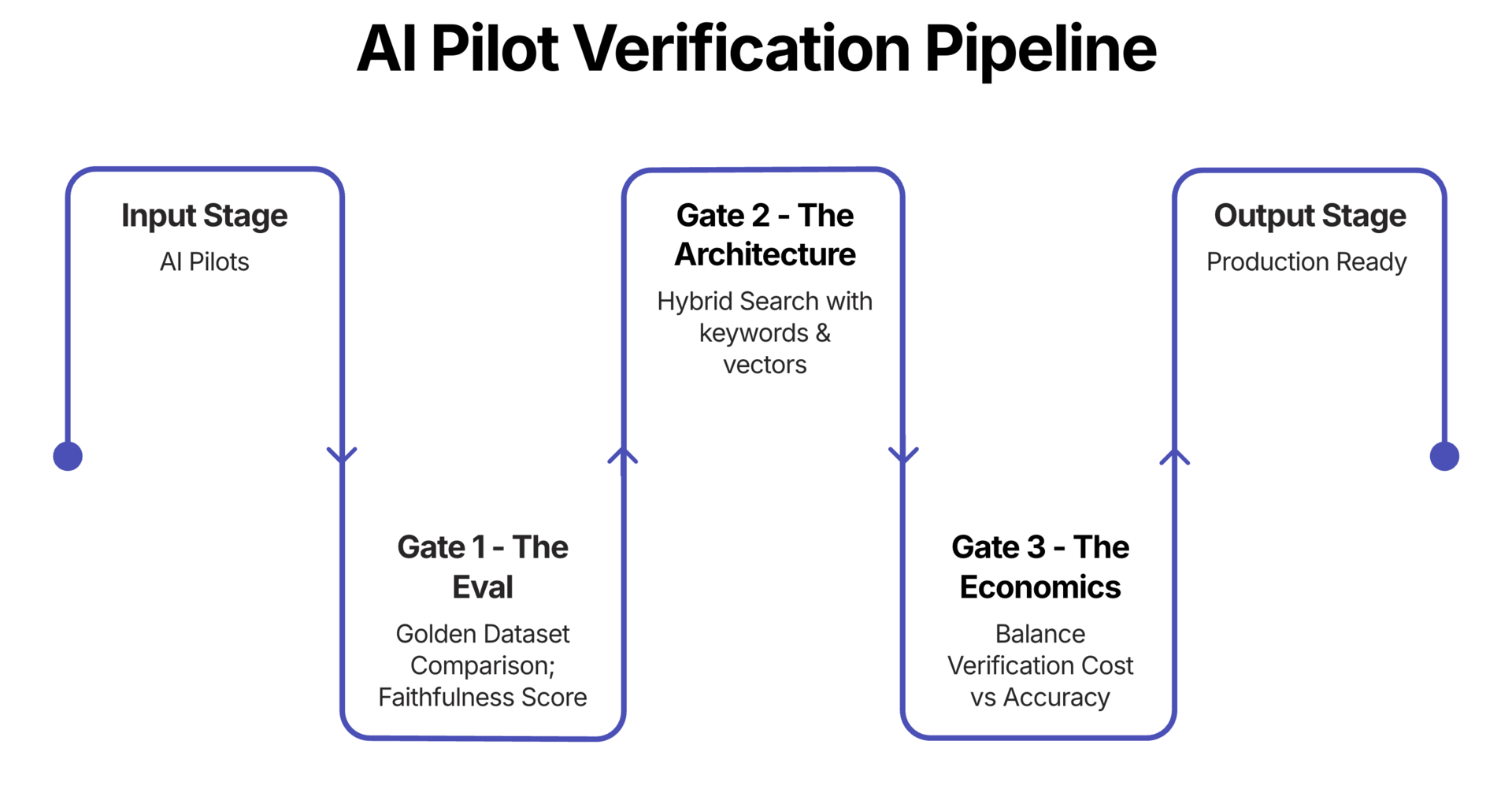
1. The “Vibe Check” vs. The Unit Test#
Most enterprise pilots are evaluated on “vibe prompting.” A developer builds a chatbot, shows it to the Head of Sales, asks a few questions about Q3 revenue, and if the bot answers correctly, the pilot is deemed a “success.”
This is madness. We do not accept bridges built on “vibes,” yet stochastic software is accepted on the same basis. A “vibe check” is not a unit test. It is blind to Drift and Edge Cases.
The Diagnosis: If a team cannot provide a programmatic, automated evaluation score (an “Eval”) for a pilot, it is not a software project; it is a one-off magic trick.
The Kill Criterion: Ask for the Faithfulness Score (a metric measuring if the AI’s answer is actually supported by the data). If they cannot provide it, or if it is below 0.9, the project either needs to be killed or reengineered.
The Fix: Mandate “Evaluation Driven Development.” Before a single line of code is written, define a “Golden Dataset”—100 pairs of Questions and Verified Answers. Every time the model is updated, it runs against this dataset. Frameworks like Ragas or DeepEval are used to generate hard numbers:
Faithfulness: Does the answer hallucinate?
Context Precision: Did the retrieval system actually find the right document, or did it get lucky?
If it cannot be measured, it cannot be shipped.
2. RAG Rot: Why The “Library” is Toxic#
Retrieval-Augmented Generation (RAG) is the current standard architecture for enterprise AI. It finds relevant documents and summarises them. The problem is Scale.
The “Lost in the Middle” Phenomenon: Large Language Models (LLMs) have a cognitive bias. They are great at reading the beginning and end of a text but frequently ignore information buried in the middle. If a pilot retrieves 20 documents and the critical clause is in document #10, the AI will likely miss it.
Context Poisoning: In a demo, data is clean. In production, data is a swamp. If an attacker (or just a lazy employee) embeds conflicting instructions or white-text keywords into a PDF, they can hijack the model’s reasoning. A single “poisoned” document in a retrieval batch can destroy the reliability of the entire answer.
The Kill Criterion: Ask the engineering team: “What is the retrieval strategy?” If the answer is “We just use standard vector search,” the project is likely doomed at scale. Standard vector search is “dumb”—it matches keywords but misses meaning.
The Fix: Hybrid Search with a Re-ranking step is required. This is non-negotiable for enterprise use cases. A “Cross-Encoder” (a smarter, slower model) is used to double-check the documents retrieved by the fast vector search. It ensures the AI is only fed the highest-quality data. Yes, it adds 300ms of latency. But 300ms of latency is better than a 10% hallucination rate.
3. The Unit Economics of “Verification Debt”#
This is the financial killer. AI investment is often justified with “Labor Arbitrage”—replacing expensive human time with cheap GPU time. But the Cost of Verification is frequently ignored.
If an AI Lawyer drafts a contract in 30 seconds (cost: €0.50), but a human Partner must spend 2hrs reviewing it line-by-line because they don’t trust the AI (cost: €200), money has not been saved. It has been lost.
This is Verification Debt. Every time an AI outputs a low-confidence answer, it creates a debt that a human must pay.
There is one more problem with costly verification — it reduces an experienced human to the role of ‘AI verifier’, which is far from satisfying.
The Kill Criterion: Calculate the Cost Per Successful Query (CPSQ).
$$ CPSQ = \frac{\text{Total Infrastructure Cost} + \text{Human Verification Cost}}{\text{Number of Accurate Responses}} $$
If the CPSQ is higher than the cost of the old manual process, the pilot is a “Zombie.” It is burning cash with every query.
The Fix:
Kill low-accuracy workflows. If the model cannot reach 95% automated accuracy, the human verification cost will destroy the ROI.
Agentic Self-Correction. Architect the system to check its own work. If the confidence score is low, the AI should refuse to answer rather than guessing. A “I don’t know” is infinitely cheaper than a plausible lie.
⠀
The Briefing#
Ethics Has Hardened into Infrastructure & Geopolitics#
The Montreal AI Ethics Institute’s latest State of AI Ethics Report (Vol. 7) serves as an obituary for the era of “soft ethics.” The report documents a decisive shift: “AI Safety” is being rapidly rebranded as “AI Security,” driven by the diverging regulatory architectures of the US, China, and the EU.
For the enterprise leader, the report flags two critical risks that are no longer theoretical:
Resource Constraints: The environmental analysis confirms that data centre water and energy consumption are moving from ESG footnotes to hard operational bottlenecks.
Sovereignty Traps: Middle-power nations are struggling to maintain “AI Sovereignty” against US/China tech hegemony. If your stack relies entirely on foreign APIs, your operational resilience is now a geopolitical variable.
⠀ The Takeaway: Stop viewing “ethics” as a PR exercise. It has morphed into supply chain resilience and regulatory compliance. If your governance strategy relies on high-level principles rather than engineering controls for compute sovereignty and resource efficiency, you are exposed.
Your AI ROI Problem is Behavioral, Not Technical#
A new analysis from Harvard Business Review (Nov 2025) diagnoses the root cause of the industry’s staggering 95% AI pilot failure rate: leaders are managing AI adoption as a technology purchase rather than a behavioral engineering challenge.
For the enterprise leader, the report identifies three “human glitches” that kill ROI:
Loss Aversion: Employees irrationally cling to inefficient manual workflows because they fear the “loss” of autonomy more than they value the “gain” of productivity.
The Error Asymmetry: Teams will forgive human colleagues for incompetence but will abandon an AI system after a single visible error.
Frictionless Failure: Making AI “seamless” backfires. Without “purposeful friction” that forces human scrutiny, users feel a loss of control and disengage.
⠀ The Takeaway: Stop optimizing your model’s weights and start optimizing your deployment psychology.
Reframe the Narrative: Explicitly position AI as an “augmenter” (force multiplier), never a “replacement,” to bypass loss aversion triggers.
Engineer Control: Deliberately design friction into the UI—require human sign-off at key stages—to restore perceived control and trust.
Co-Design or Die: If your end-users didn’t help define the training data, they will reject the output.
The “Agentic” Gap is an Org Chart Problem#
Capgemini’s latest CMO Playbook reveals an efficiency gap: while 70% of marketing leaders believe “Agentic AI” will be transformative, only 7% report any actual boost in marketing effectiveness.
Why the disconnect? The report identifies a structural failure:
Loss of Control: 55% of AI initiatives are now funded by IT, not Marketing. CMO influence on critical decisions has plummeted from 70% to 55% in two years.
The Automation Lie: Despite the hype, only 15% of leaders say low-value tasks are actually being automated. Teams are still manually managing “AI” tools instead of orchestrating autonomous agents.
⠀ The Takeaway: This is not a technology failure; it is a governance failure. Marketing cannot deploy effective autonomous agents if IT controls the budget but lacks the domain context.
The Fix: Stop treating AI as an IT procurement ticket.
The Metric: If your “AI Agent” isn’t autonomously closing tickets or campaigns without human intervention, it’s just a chatbot.
The Action: Re-align the CMO-CIO axis. Marketing defines the logic and outcomes; IT provides the infrastructure and security rails.
Conclusion — the Monday Morning Question#
In the next weekly status meeting, ask the Data or Engineering Lead this single question:
“Show me the ‘Faithfulness’ score for our lead pilot, and the automated test suite that generated it.”
If they give a blank stare, or show a spreadsheet where the Project Manager marked outputs as “Good,” pause the project. It is flying blind.
For those staring at a dashboard of 15 “Green” pilots that somehow never seem to launch, it is often difficult to get an objective view from inside the machine.
If you need support applying these “Kill Criteria” to your portfolio, or simply want to sanity-check your evaluation strategy, reply to this email. I am always open to discussing how to bring this level of engineering rigour to your innovation process.
Stay balanced,
Krzysztof Goworek
Until next time, build with foresight.
Krzysztof